質問45
Azure Synapse Analyticsでエンタープライズデータウェアハウスを設計しています。
あなたは、Web サイト訪問のファクト・テーブルを持つことを計画しています。テーブルは約 5 GB になります。
このテーブルにどのディストリビューション・タイプとインデックス・タイプを使用するかを推奨する必要があります。そのソリューションは、最速のクエリ・パフォーマンスを提供しなければなりません。
何をお勧めしますか?回答するには、回答欄で適切な選択肢を選んでください。
注意:各選択肢の正誤は1点満点とする。
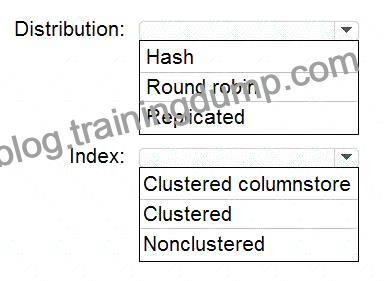

説明
ボックス 1: ハッシュ
以下のような場合は、ハッシュ分散テーブルの使用を検討する:
ディスク上のテーブル・サイズが2GBを超えている。
このテーブルでは、挿入、更新、削除の操作が頻繁に行われる。
ボックス2:クラスター型カラムストア
クラスタ化されたカラムストア・テーブルは、最高レベルのデータ圧縮と最高のクエリ・パフォーマンスの両方を提供します。
参考までに:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribu
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-index
トピック1、Litware, inc.
ケーススタディ
これはケーススタディです。ケーススタディーは個別に時間を計ることはありません。各ケースを完了するために、好きなだけ試験時間を使うことができます。ただし、本試験ではケーススタディやセクションが追加される場合があります。与えられた時間内に、本試験で出題されるすべての問題を解き終えることができるよう、時間を管理してください。
ケーススタディに含まれる質問に答えるには、ケーススタディに記載されている情報を参照する必要があります。ケーススタディーには、ケーススタディーで説明されているシナリオに関する詳細情報を提供する展示物やその他の資料が含まれている場合があります。各問題は、このケーススタディの他の問題とは独立しています。
このケーススタディの最後には、復習画面が表示されます。この画面で解答を見直し、次のセクションに進む前に変更を加えることができます。新しいセクションを開始した後、このセクションに戻ることはできません。
ケーススタディを始めるにあたって
このケーススタディの最初の質問を表示するには、「次へ」ボタンをクリックします。質問に回答する前に、左ペインのボタンを使用してケース スタディの内容を確認します。これらのボタンをクリックすると、ビジネス要件、既存環境、問題文などの情報が表示されます。ケース スタディに [すべての情報] タブがある場合、表示される情報は、後続のタブに表示される情報と同じであることに注意してください。質問に答える準備ができたら、[質問] ボタンをクリックして質問に戻ります。
概要
は、全米で300 のコンビニエンスストアを所有、運営している。同社は様々なパッケージ食品や飲料、サンドイッチやピザなどの惣菜を販売している。
リトウェアにはロイヤリティ・クラブがあり、会員は会計時に会員番号を伝えることで、特定の商品を毎日割引価格で購入できる。
リトウェアは、Microsoft Power BIを使ったデータ分析を好むビジネスアナリストと、Azure Databricksノートブックでのデータ分析を好むデータサイエンティストを雇用している。
必要条件
事業目標
Litwareは、Azureに新しいアナリティクス環境を構築し、以下の要件を満たしたいと考えています:
店舗全体の在庫レベルを見る。データはできるだけリアルタイムに更新されなければならない。
過去のデータに対してアドホックな分析クエリーを実行し、ロイヤルティクラブ割引が割引商品の売上を増加させるかどうかを特定する。
4時間ごとに、販売データから過去の需要に基づいて、惣菜を何品作るかを店の従業員に通知する。
技術要件
リトウェアは以下の技術的要件を挙げている:
ビジネス目標を達成するために必要なさまざまなAzureサービスの数を最小限に抑える。
可能な限りPaaS(Platform as a Service)サービスを利用し、リトウェアが管理する必要がある仮想マシンのプロビジョニングを回避する。
分析データストアは、社内のオンプレミスネットワークとAzureサービスからのみアクセスできるようにする。
可能な限り、Azure Active Directory(Azure AD)認証を使用してください。
セキュリティを設計する際には、最小特権の原則を使用する。
分析データストアにデータをロードする前に、Azure Data Lake Storage Gen2でInventoryデータをステージングする。Litwareは、データが使用されなくなったら、Data Lake Storageから一時的なデータを削除したいと考えています。
更新日が14日以上前のファイルは削除する必要があります。
ビジネスアナリストが電話番号などの顧客連絡先情報にアクセスするのを制限する。
破損や偶発的な削除が発生した場合、分析データストアのコピーを1時間以内に迅速に復元できるようにする。
計画された環境
リトウェアは以下の環境を導入する予定だ:
アプリケーション開発チームは、POSシステムから店舗番号、日付、時間、商品ID、顧客ロイヤルティ番号、価格、割引額などのリアルタイムの販売データを受け取り、Azureのデータストレージに出力するAzureイベントハブを作成する。
名前、連絡先情報、ロイヤルティ番号などの顧客データは、SaaSアプリケーションであるSalesforceから取得され、8時間に1回Azureにインポートされます。行の更新日は、ソーステーブルでは信頼されません。
商品ID、商品名、カテゴリーを含む商品データはSalesforceから取得し、8時間に1回Azureにインポートできます。行の更新日は、ソース テーブルでは信頼されません。
日々の在庫データは、プライベート・ネットワーク上にあるマイクロソフトのSQLサーバーから送られてくる。
リットウェアは現在、5TBの過去の販売データと100GBの顧客データを保有している。同社は今後1年間、毎月約100GBの新規データを見込んでいる。
リトウェアはFoodPrepというカスタム・アプリケーションを構築し、4時間ごとに何品目の惣菜を生産すべきかという計算結果を店舗の従業員に提供する。
リトウェアは、Azure ExpressRouteやオンプレミスネットワークとAzure間のVPNを実装する予定はありません。

